A project to learn Distributed Systems
In the last post, I tried to narrow down what are the areas in distributed systems I was going to focus on at Recurse Center. But haven’t clearly explained the project I had in my mind. This post is to fill that gap.
The Problem
A simple health checker of ‘n’ servers. Given a bunch of servers to track the health check, it monitors the health checks of those servers and provide interface to get the health check status of those servers.
We have two version of project. First version is a naive way of solving it via single process. Then we build on top it solving the same problem with multiple processes.
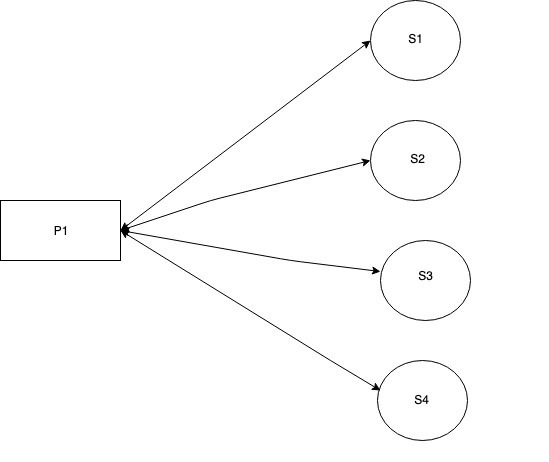
Version 1 (Single Process)
Here we solve the above problem by starting single process that takes ‘n’ input servers and monitor health check by HTTP polling its health check endpoints for every interval ‘t’. Important thing here is ‘single process’ make request to all the input servers.
Pros
- Simple to understand and implement.
Cons
- Single Point Of Failure, if that single process crashes, none of the severs will be monitored.
- Doesn’t scale for huge number of input servers (say in the order of 10K or so)
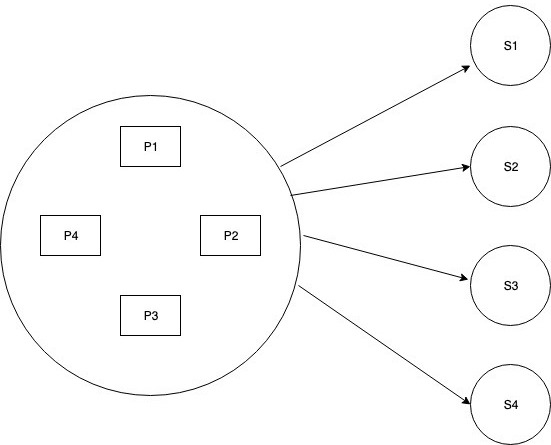
Version 2 (Multiple Process)
Here we distribute the work of health checking across multiple processes(preferably in multiple nodes). Even now the system is solving the same problem but instead of single process, multiple processes are involved in making health check requests to given ‘n’ servers.
Pros
- We fixed the two Cons of version 1. No Single Point of Failure(if one process crashes, some other process can take of monitoring) and Scales well (we can add more process if ‘n’ increases)
Cons
- System is more complex now and difficult to reason about
- Implementation also is much more harder now.
Why Version 2 is hard to understand and implement? (a.k.a Fun part!!)
Try to think about following questions.
- Now there are ‘m’ processes, How do you decide which process does the health check of which server? Can every process make request to every servers?
- To make the system more available, the client should be able to connect to any ‘process’ (say ‘p’) and get health information of any servers that might not have health checked by process ‘p’. So every process have to share its state with every other processes.
- How does these processes talk to each other to share its state? or can we just have shared storage with all the processes?
- If two process have conflicting states (say p1 says s1 is healthy while p2 says s1 is unhealthy) how does it resolve conflict and converge to the same value?
- To resolve conflict between processes, how do you know which event happened before what?
- If you are using multiple process to solve problem, there going to be failure of process? How do you replace these failure processes or even nodes?
- What happens to the state of those failed processes?
All these fundamental questions are specific problems in the area of distributed systems! Let use proper name from now on :)
Ownership
In naive way, we can make every process ‘p’ can make health requests to every servers right? well, that’s what is called DDOS! (imagine your server keep getting ‘m’ requests per second and ‘m’ is in order of 10K or so)
How to decide which process do health check of which server? What we need is ownership for those severs! Say P1 is owner of S1 and S2 only P1 do health check for S1 and S2.
We also need some kind of priorities of Ownership, Say if P1 is crashed or not available, someone other process has to take care of P1 servers.
Failure Detectors
We need a system to handle failure of processes. Its kind a like health checker for a health checker (well, actually it is). Basically failure detectors are needed to replace the faulty process with new ones.
Gossip
Since not all the process do health check of all the servers, these process have to communicate to share state (so that if client have query like “Tell me all the servers that are unhealthy!”, the query can be served by any process). How do these nodes communicate with each other (say for exchanging states).
That’s where Gossip comes in. Gossip is kinda like asynchronous way of sharing states without any locks or something. It can happen at the background while each process still progressing by doing health checks.
Convergence
When sharing the state across the process, there can be conflicts. Say P1 says S1 is healthy while P2 says S1 is unhealthy. How do you resolve the conflicts?
There are two ways you could approach this problem.
- By introducing total ordering between all the events happening inside the system. Events can be “doing health check or saving its health check information”
- Just by having partial ordering between(causality)
Total order can be introduced by using some kind of consensus protocol (say raft). We already have Key value store like etcd and consul uses them. So we could use etcd to store the states of processes. All the read/write of states happens through this shared key value store.
Once we have total ordering we can always say event A happens-before event B for any events.
But we have to pay the penalty of co-ordination of some kind for every state change (say persisting health check info). This is because of underlying consensus protocol works in such a way that these nodes have to agree on some state before proceeding further (via Quorum or 2PC)
Another interesting way to solve this is issue is with just partial ordering. This is where Causality plays role. The basic idea is we don’t have to worry about ordering of two events say A and B of different nodes unless they are Casually related (one event causes the other event)
And these causality can be tracked by Version Vectors. So we share states as DeltaCRDT and resolve conflicts via Version Vectors (also part of the sharing state)
Build the project iteratively (each problem can be solved independently)
- A simple health checker(Version 1) in Rust - use it to get familiar with Rust
- Solve Ownership problem - Given list of serves and processes involved, spit out ownership in priority order.
- Solve Failure detectors problem - Implement SWIM based Failure Detectors (take inspiration from Hashicorp’s memberlist project)or reuse any library in Rust
- Solve convergence problem via Consensus - Find some etcd alternative in Rust and play with it
- Solve Convergence problem via Gossip + DeltaCRDT + Version Vectors - Try to implement each from the scratch in the context of simple key value store (to avoid worrying about other components)
- Putting it all together, Distributed Health Checker (Version 2)
That’s the project idea to learn distributed systems.